好代码的标准
“好代码的检验标准就是人们是否能轻而易举地修改它。好代码应该直截了当:有人需要修改代码时,他们应能轻易找到修改点,应该能快速做出更改,而不易引入其他错误。一个健康的代码库能够最大限度地提升我们的生产力,支持我们更快、更低成本地为用户添加新特性。为了保持代码库的健康,就需要时刻留意现状与理想之间的差距,然后通过重构不断接近这个理想。”
重构的节奏
“开展高效有序的重构,关键的心得是:小的步子可以更快前进,请保持代码永远处于可工作状态,小步修改累积起来也能大大改善系统的设计。这几点请君牢记,其余的我已无需多言”
重构的原则
何谓重构
“重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。” “重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下,调整其结构。
所以,我可能会花一两个小时进行重构(动词),其间我会使用几十个不同的重构(名词)。 “重构的关键在于运用大量微小且保持软件行为的步骤,一步步达成大规模的修改。每个单独的重构要么很小,要么由若干小步骤组合而成。因此,在重构的过程中,我的代码很少进入不可工作的状态,即便重构没有完成,我也可以在任何时刻停下来。整个过程中也不会花任何时间来调试“
“结构调整”(restructuring)来泛指对代码库进行的各种形式的重新组织或清理,重构则是特定的一类结构调整。”
两顶帽子
“Kent Beck提出了“两顶帽子”的比喻。使用重构技术开发软件时,我把自己的时间分配给两种截然不同的行为:添加新功能和重构” 在实际开发过程中,两顶帽子是交替进行的。
为何重构
用于以下几个目的: “重构改进软件的设计” “重构使软件更容易理解” “重构帮助找到bug” “重构提高编程速度” 其中最核心的 是最后一条 重构能提高编程的速度,重构的唯一目的就是让我们开发更快,用更少的工作量创造更大的价值” “我们之所以重构,因为它能让我们更快——添加功能更快,修复bug更快。一定要随时记住这一点,与别人交流时也要不断强调这一点。重构应该总是由经济利益驱动。程序员、经理和客户越理解这一点,“好的设计”那条曲线就会越经常出现”
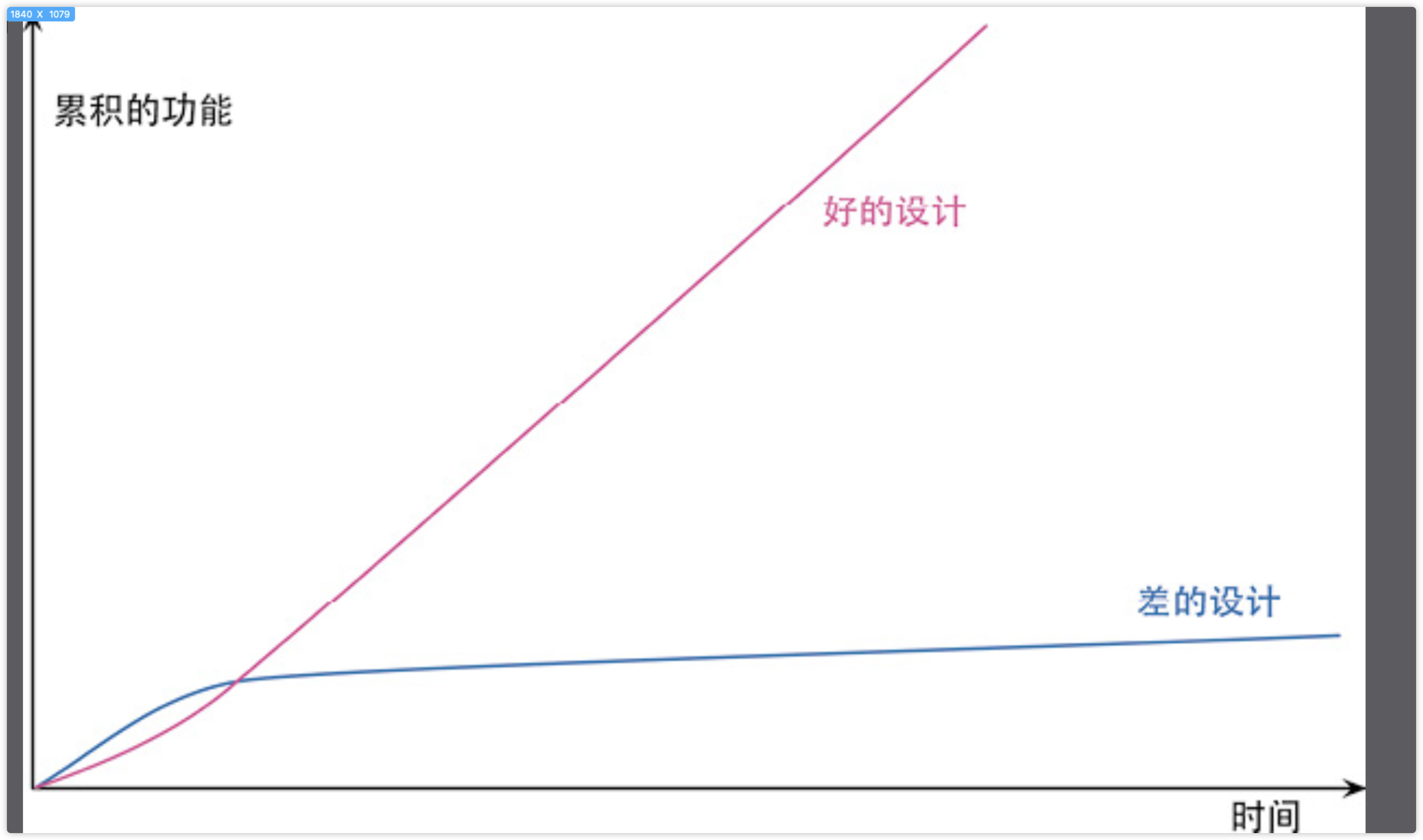 “设计耐久性假说”:通过投入精力改善内部设计,我们增加了软件的耐久性,从而可以更长时间地保持开发的快速。”
“设计耐久性假说”:通过投入精力改善内部设计,我们增加了软件的耐久性,从而可以更长时间地保持开发的快速。”
何时重构
“三次法则“:Don Roberts给了我一条准则:第一次做某件事时只管去做;第二次做类似的事会产生反感,但无论如何还是可以去做;第三次再做类似的事,你就应该重构。 “重构的最佳时机就在添加新功能之前” “修复bug时的情况也是一样。在寻找问题根因时,我可能会发现:如果把3段一模一样且都会导致错误的代码合并到一处,问题修复起来会容易得多。或者,如果把某些更新数据的逻辑与查询逻辑分开,会更容易避免造成错误的逻辑纠缠。用重构改善这些情况,在同样场合再次出现同样bug的概率也会降低。” “这是一件很重要而又常被误解的事:重构不是与编程割裂的行为。你不会专门安排时间重构,正如你不会专门安排时间写if语句。我的项目计划上没有专门留给重构的时间,绝大多数重构都在我做其他事的过程中自然发生”
“肮脏的代码必须重构,但漂亮的代码也需要很多重构”:“在写代码时,我会做出很多权衡取舍:参数化需要做到什么程度?函数之间的边界应该划在哪里?对于昨天的功能完全合理的权衡,在今天要添加新功能时可能就不再合理。好在,当我需要改变这些权衡以反映现实情况的变化时,整洁的代码重构起来会更容易”
“优秀的程序员知道,添加新功能最快的方法往往是先修改现有的代码,使新功能容易被加入”
“所以,软件永远不应该被视为“完成”。每当需要新能力时,软件就应该做出相应的改变。越是在已有代码中,这样的改变就越显重要”
重构与性能
对于性能:“哪怕你完全了解系统,也请实际度量它的性能,不要臆测。臆测会让你学到一些东西,但十有八九你是错的” 我们要用数据说话,而不是凭感觉做优化
“我编写构造良好的程序,不对性能投以特别的关注,直至进入性能优化阶段——那通常是在开发后期。一旦进入该阶段,我再遵循特定的流程来调优程序性能。” 重构时不需要特别考虑性能问题,处理完了,如果性能有问题,再调优。
“在性能优化阶段,我首先应该用一个度量工具来监控程序的运行,让它告诉我程序中哪些地方大量消耗时间和空间。这样我就可以找出性能热点所在的一小段代码。然后我应该集中关注这些性能热点,并使用持续关注法中的优化手段来优化它们。由于把注意力都集中在热点上,较少的工作量便可显现较好的成果。即便如此,我还是必须保持谨慎。和重构一样,我会小幅度进行修改。每走一步都需要编译、测试,再次度量。如果没能提高性能,就应该撤销此次修改。我会继续这个“发现热点,去除热点”的过程,直到获得客户满意的性能为止。”
“短期看来,重构的确可能使软件变慢,但它使优化阶段的软件性能调优更容易,最终还是会得到好的效果”
坏代码的味道
“命名是编程中最难的两件事之一”
“我们遵循这样一条原则:每当感觉需要以注释来说明点什么的时候,我们就把需要说明的东西写进一个独立函数中,并以其用途(而非实现手法)命名。我们可以对一组甚至短短一行代码做这件事。哪怕替换后的函数调用动作比函数自身还长,只要函数名称能够解释其用途,我们也该毫不犹豫地那么做。关键不在于函数的长度,而在于函数“做什么”和“如何做”之间的语义距离”
“如何确定该提炼哪一段代码呢? 一个很好的技巧是:寻找注释。如果代码前方有一行注释,就是在提醒你:可以将这段代码替换成一个函数,而且可以在注释的基础上给这个函数命名。就算只有一行代码,如果它需要以注释来说明,那也值得将它提炼到独立函数中去 条件表达式和循环常常也是提炼的信号:如果有多个switch语句基于同一个条件进行分支选择,就应该使用以多态取代条件表达式(272)。 至于循环,你应该将循环和循环内的代码提炼到一个独立的函数中。如果你发现提炼出的循环很难命名,可能是因为其中做了几件不同的事。如果是这种情况,请勇敢地使用拆分循环(227)将其拆分成各自独立的任务”
“全局数据印证了帕拉塞尔斯的格言:良药与毒药的区别在于剂量。有少量的全局数据或许无妨,但数量越多,处理的难度就会指数上升。即便只是少量的数据,我们也愿意将它封装起来,这是在软件演进过程中应对变化的关键所在”
“如果可变数据的值能在其他地方计算出来,这就是一个特别刺鼻的坏味道。它不仅会造成困扰、bug和加班,而且毫无必要。消除这种坏味道的办法很简单,使用以查询取代派生变量”
“如果发生变化的两个方向自然地形成了先后次序(比如说,先从数据库取出数据,再对其进行金融逻辑处理),就可以用拆分阶段(154)将两者分开,两者之间通过一个清晰的数据结构进行沟通。如果两个方向之间有更多的来回调用,就应该先创建适当的模块,然后用搬移函数(198)把处理逻辑分开。如果函数内部混合了两类处理逻辑,应该先用提炼函数(106)将其分开,然后再做搬移。如果模块是以类的形式定义的,就可以用提炼类(182)来做拆分。”
“将总是一起变化的东西放在一块儿。数据和引用这些数据的行为总是一起变化的,但也有例外。如果例外出现,我们就搬移那些行为,保持变化只在一地发生”
“数据项就像小孩子,喜欢成群结队地待在一块儿。你常常可以在很多地方看到相同的三四项数据:两个类中相同的字段、许多函数签名中相同的参数。这些总是绑在一起出现的数据真应该拥有属于它们自己的对象。首先请找出这些数据以字段形式出现的地方,运用提炼类(182)将它们提炼到一个独立对象中。然后将注意力转移到函数签名上,运用引入参数对象(140)或保持对象完整(319)为它瘦身。这么做的直接好处是可以将很多参数列表缩短,简化函数调用。是的,不必在意数据泥团只用上新对象的一部分字段,只要以新对象取代两个(或更多)字段,就值得这么做。” “一个好的评判办法是:删掉众多数据中的一项。如果这么做,其他数据有没有因而失去意义?如果它们不再有意义,这就是一个明确信号:你应该为它们产生一个新对象”
“有用的类被创建出来,大量的重复被消除,后续开发得以加速,原来的数据泥团终于在它们的小社会中充分发挥价值。 如果你有一组总是同时出现的基本类型数据,这就是数据泥团的征兆,应该运用提炼类和引入参数对象(140)来处理” 对于循环语句:我们可以使用以管道取代循环,管道操作(如filter和map)可以帮助我们更快地看清被处理的元素以及处理它们的动作”
“如果你看到用户向一个对象请求另一个对象,然后再向后者请求另一个对象,然后再请求另一个对象……这就是消息链。在实际代码中你看到的可能是一长串取值函数或一长串临时变量。采取这种方式,意味客户端代码将与查找过程中的导航结构紧密耦合。一旦对象间的关系发生任何变化,客户端就不得不做出相应修改。这时候应该使用隐藏委托关系(189)”
1
2
3
4
5
6
7
8
cosnt a = this.obj.a
=>
const this.getA;
class{
getA(){
return this.obj.a
}
“纯数据类常常意味着行为被放在了错误的地方。也就是说,只要把处理数据的行为从客户端搬移到纯数据类里来,就能使情况大为改观。”
提炼函数
“何时应该把代码放进独立函数”,最合理的观点是:“将意图和实现分开” 创造一个函数,并根据这个函数的意图来对他进行命名(以它“做什么”而不是它 “怎么做”命名)ps:个人总结:以动词开头会比较好